
 Message virtuel de J.E. à G.O.E., mars 1977: Tu sais que tu es la personne que j’aime le plus au monde. Tu sais aussi que depuis longtemps je dis que si jamais les conditions de vie deviendront insupportables, j’y mets fin. Ma condition médicale vient de devenir insupportable. La seule chose qui m’empêcherait de faire comme je souhaiterais serait que tu me dise que ça te ferait plus de peine que ça m’en épargnerait. J’attends ta décision, mais je crois que je la sais déjà.
Message virtuel de J.E. à G.O.E., mars 1977: Tu sais que tu es la personne que j’aime le plus au monde. Tu sais aussi que depuis longtemps je dis que si jamais les conditions de vie deviendront insupportables, j’y mets fin. Ma condition médicale vient de devenir insupportable. La seule chose qui m’empêcherait de faire comme je souhaiterais serait que tu me dise que ça te ferait plus de peine que ça m’en épargnerait. J’attends ta décision, mais je crois que je la sais déjà.
Toons ‘n Tears

Re: “Music and speech share a code for communicating sadness in the minor third”
Interesting finding, but so many questions arise, the foremost being cause/effect:
We live in a world of film-music where “emotions” are punctuated by certain musical clichés (dissonance: tension; consonance: relief; major: cheery; minor: teary).
Of course the clichés may have been chosen because of their innate expressive meaning, but the reverse is also possible, perhaps just as possible: the Frenchman for whom an olympic gold win by a countryman immediately evokes the Marseillaise…
So, yes, the cultural universality of all this remains to be tested, as the author notes; otherwise we are just dealing with self-reinforcing habitual associations in Western pop “culture.”
 (I would be more inclined to believe in the inborn affective connotations of simpler acoustic properties, such as volume (loud: alarm; quiet: calm), tempo (fast: agitated; slow: calm) and timbre (some vocalizations are shrill and grating, so sound urgent; others sound soothing). Also, there seems to be a lot of scope for looking at movement and dance, where some movements look intrinsically menacing, conciliatory, beckoning, agitated, etc., although there is plenty of room for effects of culture, convention and habit there too.)
(I would be more inclined to believe in the inborn affective connotations of simpler acoustic properties, such as volume (loud: alarm; quiet: calm), tempo (fast: agitated; slow: calm) and timbre (some vocalizations are shrill and grating, so sound urgent; others sound soothing). Also, there seems to be a lot of scope for looking at movement and dance, where some movements look intrinsically menacing, conciliatory, beckoning, agitated, etc., although there is plenty of room for effects of culture, convention and habit there too.)
I of course do believe that music expresses some deep universals in human affect, but it would take far stronger evidence than this author’s findings to show that that belief is right, especially for major/minor! (By the way, I think a minor 6th is even more of a tear-jerker than a minor 3rd…)
If the affective connotations of some vocal or other bodily gestures (and states: let’s not forget facial expressions, trembling and tears) are hard-wired into our brains, it is not that they are part of “language” too. Language is language even if it is written, unpunctuated by movement or intonation. The vocal and visual aspects of language are simply somatic: they come with the territory whenever we do anything with our bodies, especially inasmuch as it is being transmitted to or received by other bodies like our own.
With the globalization of Hollywood’s tear-jerkers, I doubt it is still possible to test whether or not certain acoustic clichés are cultural, let alone evolutionary universals, except maybe with isolated infants and hunter-gatherers! And the “Mozart effects” we seek are likely to turn out to be just as much MoTown effects. Rather like the Schenkerian reduction of all harmony to 5/1… ;>)
Oleaginous Juggernaut

The short-sightedness, greed,
deception and self-deception
of the 4/20 ocean oil drilling disaster
are probably just a faint foretaste
of the bitter endgame
on the deepwater horizon
for our incorrigible genotype.
Posthumous Posturings 2010-06-09
Tribute?
For whom?
Testimony?
To whom?
Relief
From tribulation?
For shame.
Airing conflict?
Reality TV yen
Writ large?
So small.
<i>Mach dich nicht
So klein
Du bist nicht
So groβ.</i>
The linguistic turn?
Biogenetic imperative?
The selfish gene
Spawning its
Narcissistic memes?
Yet you, lifelong,
Immunized me
Against solipsism.
I refute it thus.
Tacet 2010-06-02
That lifelong sound
That has accompanied me every moment
Since the day of my birth
So constant it was inaudible
Now you’re gone
And I hear only its absence
Isn’t Public Deficit Financing a Ponzi Pyramid?
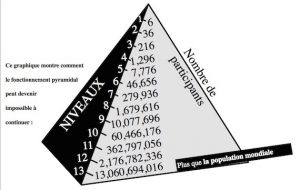
Isn’t public deficit financing a Ponzi Pyramid, doomed to collapse sooner or later as surely as the Madoff meltdown? (Is Environmental Hedging not much the same thing?) Our species is reputed special for being uniquely able to “delay gratification” (short-term pain for long-term gain) — but with it seems to have come an appetite for the opposite: Short-term personal gain for others’ long-term pain.
Sociopathic Sanctimony
It is hard to say whose brand of betrayal is the most repugnant: that of the pitiless pedants, or the well-meaners purporting to be prolonging sufferers’ pain to protect others, or the metaphysical monsters who solemnly invoke the sanctity of the “right” of another to continue suffering on account of an article of faith to which the monster subscribes but the sufferer does not.
The sociopathic sanctimony of those who raise the slightest justification for the unforgivable denial of Chantal Sébire‘s escape from her relentless suffering is beyond words.
Sarkozy, meanwhile, confirms both his jadedness and his jejuneness.
There is a chaos in my head 2010-05-25
One morning,
after a night of restive distress and confusion,
you said,
with fear and resignation,
“There is a chaos in my head.”
And I saw it,
with dread,
the monster which was thereafter only to keep growing and growing,
till it overcame you
almost entirely.
And I could not help,
only tremble.
Could only yearn that you would fight it off,
defeat it,
as you always had mine.
What an unwise, unworthy investment I was.
How alone you were —
more alone than I am now,
for I had had your sustenance, lifelong,
and you had never had mine.
Or anyone’s.
2010-05-25
Faith 2010-05-23
Resisted loving your cats,
feeling it would be a betrayal of my dog,
long gone,
who so loved you.
Fancied also
(oh so fatuously)
that caring for them
(like carrying on teaching Tai Chi —
another wrongful suspect)
was diminishing your diminishing life
rather than preserving it.
Now you’re gone,
only their mute daily yearning for you,
relentless, perplexed,
to be witnessed and felt,
and all resistance is dissolved.
Remorse alone,
irremediable remorse,
for having denied you
(and them)
my love for them.
Fidelity’s a false friend.
Even an instant
may become an eternity.
Feeling alone,
immanent feeling, felt,
matters.
Few the wrongs
that can ever be righted
posthumously.
2010-05-23
Monoglot Myopia: Mordechai Richler on Canada & Quebec, Two Decades After

You can write a humorous book on laughable language laws, but not on anti-semitism, nor aboriginal rights, nor even on Franco-Canadian grievances and aspirations. Richler’s (now much-dated) book, though it contains some relevant truths and insights, and is no doubt driven by some genuine anguish on the part of the author, is, in the end, an exercise in superficial stereotyping, insensitivity and bad taste. Everything that is true in it could have been said in an uncompromising way without the gratuitous offensiveness (but then it wouldn’t have been good for laughs). But to keep it fun, most of the real core of the ethnic problems of Quebec would have had to be omitted. Perhaps a genuine outsider like Bill Bryson could have written about some of it in a detached, good-natured way. But clearly Mordechai Richler was not up to it. [And no, it does not help the book, nor the author’s understanding, that he cannot speak (only reads) French, hence can only banter with bar-buddies, one-sidedly.]