Case Study
This learning object briefly reviews as a case study the Dash et al. (2004) paper on automatic building extraction from laser scanning data.
The LiDAR data used in the present study were provided by TOPOSYS GmbH, and covers a part of the city of Karlsruhe, Germany. Data were acquired using a NIR Laser with 5 points/m2.
Reflection
What is the scanning mechanism for the TopoSys LiDAR system?
It uses a fibre optic scanning system which has the advantage of a high scanning speed, no moving parts (hence it is stable during scanning) and identical transmitting and receiving optics.
Incorrect
The following steps were taken to extract buildings from the LiDAR data:
- Extraction of a normalized digital surface model (nDSM) from the original data.
- Segmentation of the nDSM image into segments, so as to identify building segments.
- Extraction of the object border polygons from the building segments.
- Estimation of the modified standard deviation (MSD) along the boundary pixels and differentiation between building and vegetation based on uniformity of MSD values along the boundary pixels.
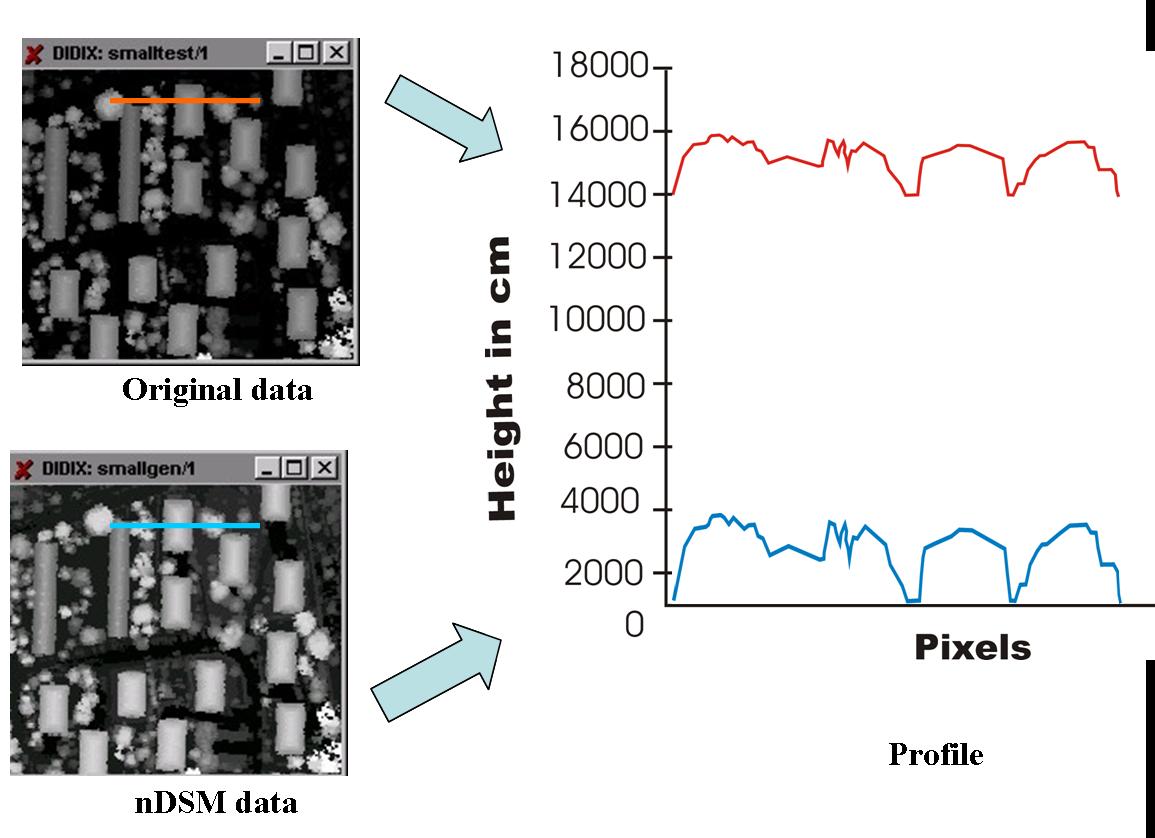
Both first and last return data were available for this study. A convex hull algorithm was used to generate the DSM and DEM and in turn, the normalised DSM. The figure below shows a profile along the same objects for DSM and nDSM. In the nDSM we can easily see the height jumps for different objects along the profile and this provides the actual heights for individual objects.
On the nDSM, textural variation in height values wass used to separate them in to various segments. The segmentation algorithm requires two threshold values. The first threshold is the minimum height above which the objects should be segmented. The second threshold is the height which should be considered while including the adjoining pixel in the same segment i.e. if the adjoining pixels are under this height then they will come under the same segment. The algorithm searches for 3×3 pixels where all the heights are above the first threshold and then tries to find the height differences of all the adjoining pixels. All those whose height difference is below the second threshold are classified as part of the same segment. This process continues until none of the adjoining pixels are below the second threshold.

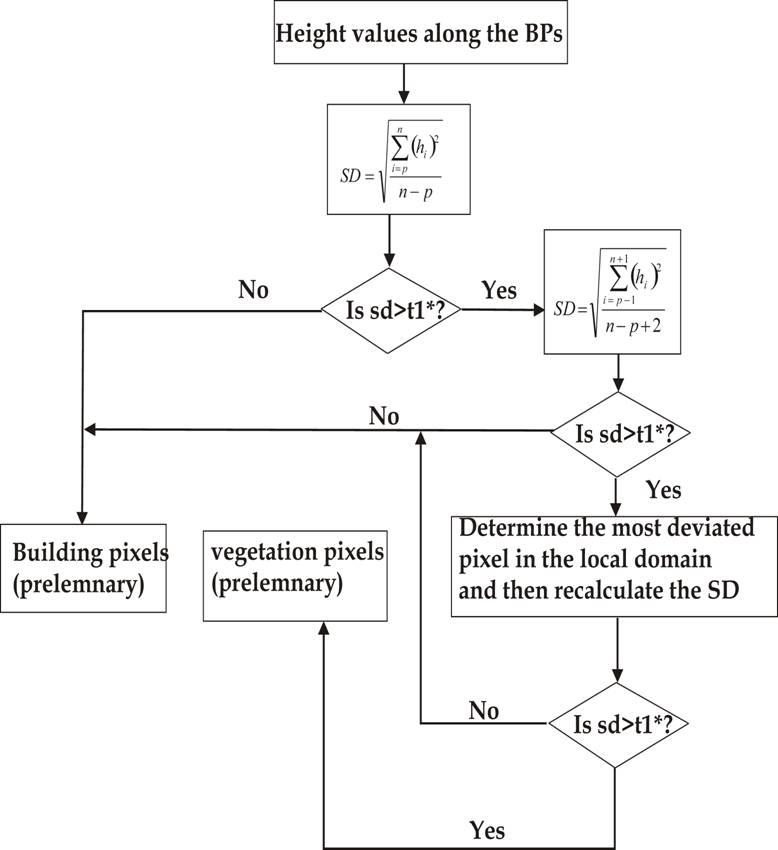
Segmentation is followed by extraction of the contour lines of each object and then application of modified standard deviation (MSD) along the contours. The MSD estimates the local standard deviation with respect to a best fit line in the form of a 5-pixel moving window along the boundary pixels. If the standard deviation is less than a certain threshold then pixels are classified as building pixels, otherwise the window size is extended and the standard deviation is recalculated and checked to see if it is less than the threshold. The process is given in the figure below:
Once the potential building polygons were extracted, a shape analysis was carried out to further remove the vegetation polygons. For each polygon, six parameters were calculated: area of polygon, sum of four biggest sides, average of all sides, length group, angle group and geometry of four biggest sides. The parameters were combined in a fuzzy based principle where individual parameters were given certain weights, for example the area of a polygon was given a higher weight than the length group. Results of the building extraction are given in the figure below. It is worth nothing that some parts of vegetation, mainly those adjacent to buildings, remain in the output and the algorithm should be improved to remove these completely.

Reference
Dash, J., Steinle, E., Singh, R. P. and Bahr, H. P. (2004) Automatic building extraction from laser scanning data: an input tool for disaster management. Advances in Space Research 33, 317–322.