Building Extraction from Airborne LiDAR Data
The objective of this learning object is to explore the challenge of extracting building objects from airborne LiDAR imagery.
Why is building extraction difficult?
Accurate extraction of buildings from LiDAR data is always challenging, because we have only geometric information in the form of sparse points. See the image below: in general, it may be difficult for a computer to identify which points belong to a building. Geometry may be useful to distinguish between man-made (regular) structures and natural (irregular) objects, but quite often it is difficult to distinguish between artificial features such as tanks or buses which have regular shapes. Even some buildings are more complex than others and in modern architecture there is frequent use of non-planar surfaces which make it even more difficult to follow the basic assumption that buildings are composed of a number of regular and planar features.

The Basic Concept of Building Extraction
Building extraction from LiDAR data is based on some key assumptions:
- Buildings points are at higher elevation with respect their local neighbourhood
- Buildings have regular shapes and are generally made of planar surfaces
- The producer has some domain knowledge about the area
Therefore, the efficiency of a building detection algorithm depends on the reliability with which it is possible to define planar surfaces. However, most of the time the algorithm may produce errors when trees are near to buildings or a few buildings with very different shapes are joined together. Quite recently, optical remote sensing data (e.g. colour photographs) have been combined with LiDAR data in an attempt to overcome these problems.
LiDAR data collected over urban areas consist of point clouds from many surfaces including vegetation, bare earth, cars and buildings. One of the first steps in building extraction from LiDAR data is to extract bare earth, often by applying a filter which removes non-ground points in the LiDAR data. This is followed by more sophisticated algorithms to extract buildings. In general, the building extraction consists of the following steps:
1. Develop a normalised DSM (nDSM) to show the variation of only above-ground objects, as terrain slope has been eliminated.
2. Threshold nDSM at different heights, on the basis that lower height objects are not related to buildings.
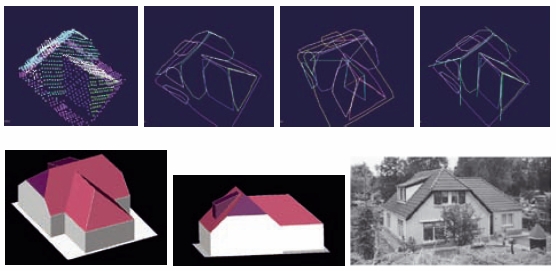
3. Find points that have similar heights and lie within the same neighbourhood (a process called segmentation). The resultant, irregular shapes correspond to the trees while regular shapes correspond to buildings. This process also helpful in finding outlines of the buildings (intersection of planes). Figure below shows steps in the automatic extraction process of 3D building from LiDAR data – segmentation → segment handling → topological analysis → line and vertex extraction (top from left to right); the extracted 3D building and results verification (bottom from left to right). (Source: Abo Akel et al., 2006)
Common methods of building extraction from LiDAR data
Building extraction occurs from non-ground datasets; extraction is either from only LiDAR data or from LiDAR and ancillary data (e.g. images). Building extraction methods can be classed as model -driven, data-driven, geometric or statistical; in reality such extraction methodologies draw upon a combination of techniques.
Model-driven approach
In this approach, first, specific assumptions are made about building models where each part of the building, particularly the roof structure, can be defined mathematically. If a scene consists of specific building/roof types, for example, gabled roofs, then all possible variations of the roof are included in the model. Complex buildings can be divided into smaller parts so that they can be replicated as a series of simpler models. The accuracy of buildings extraction by this approach is related to the performance of the algorithm in identifying planar surfaces and the point density of the data. When buildings to be extracted are complex, it is difficult to parameterise a model-driven approach to extracting buildings, and/or the LiDAR data are noisy then a data-driven approach is the best option.
Data-driven approach
Data-driven approaches include generation of a digital surface model and determination of pixels which are planar. Using connected homogeneous pixels as seeds to generate planar regions, planar facets can then be used to generate lines of intersections or edges; this method is improved by using statistical methods to minimize dependence upon a threshold in determining planes and breaklines.
Statistical approaches
Statistical approaches often use clustering or classification techniques to define planar surfaces in LiDAR data. An example of a clustering statistical approach is defining feature vectors for each LiDAR point based on a tangential plane and then using these measures to cluster points into similar surface classes based on spatial proximity. “Properties” upon which the clustering of similar LiDAR points is based are defined by the selection of feature space. With LiDAR data, the initial data space only provides the locations of data whereas feature space can provide information regarding surface normal (direction of cosines). Clustering techniques can separate different planar surfaces based upon information provided in feature space and thus form feature vectors. Similarity measures (often distance) measure the similarity of features in feature space; the type of similarity measure determines the size and shape of the cluster. Noise and data ambiguities can influence clustering results; they prevent feature vectors being calculated accurately.