Recent Comments
Archives
Categories
- No categories
Meta
10.4. Supervised Classification
Objectives
The objective of this learning object is to introduce the principles of supervised image classification, covering the user definition of land cover classes, training/site selection, generation of statistical parameters and the classification process itself. Parallelpiped, minimum distance to means and maximum likelihood classification algorithms are introduced.
Supervised image classification is a procedure for identifying spectrally similar areas on an image by identifying ‘training’ sites of known targets and then extrapolating those spectral signatures to other areas of unknown targets. It requires training data which are typical and homogeneous and the application of a set of methods, or decision rules.
The following presentation provides a summary overview of the stages involved in a supervised classification:
N/B: The slides below will not show on the webpage, but you can save/keep them on your computer and view them using the Adobe Flash Player 32 you downloaded earlier
Training/site selection
Good quality training data are needed to ‘teach’ the computer to recognise similar patterns in the imagery. These represent only a small sample of the entire image/region to be classified. Training data can be selected based on:
- Field visits
- High spatial resolution data
- Previous maps
- Investigator knowledge
- Any or all of the above
The goal is to select multiple areas for each land cover type throughout the image. The choice of training data can significantly affect the classification results!
The aim is to provide a quantitative description of the appearance of each thematic (land use) class of interest in the image. The first step must therefore be to define the classes of interest, which requires thinking carefully about the aim of the study.
The number of training pixels required to make up a sample depends on the variability and distinctiveness of the spectral response of the class. As a rule of thumb, at least 100 sites per class should be used, or at least 10 times the number of spectral bands in the image.
It is best to acquire the overall number of sample pixels from many small areas around the image rather than from just one or two areas. This allows all possible variations in the image to be accounted for.
| Good practice for training/site selection |
| Assemble information |
| Conduct field studies |
| Carefully plan selection of field observations |
| Conduct preliminary analysis of the digital scene |
| Identify prospective training areas (TA) |
| Locate TA on the image |
| Inspect signatures and statistics |
| Refine TA choice |
| Select final training data |
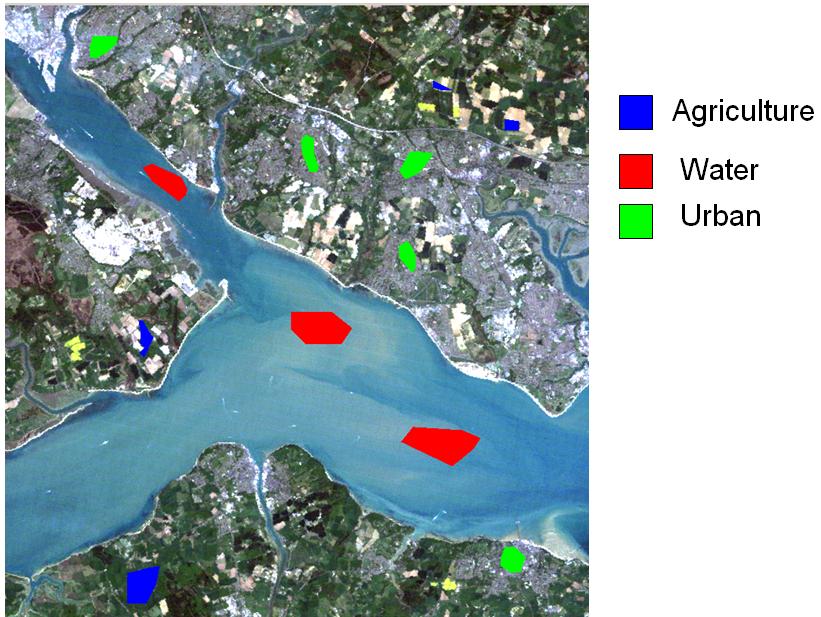
Here, possible training sites are shown for agriculture, water and urban land cover types on an image of the Solent area:
Supervised Classification Practical
Link to the practical can be found here.