Recent Comments
Archives
Categories
- No categories
Meta
10.3. Unsupervised Classification
Objectives
The objective of this learning object is to introduce the principles of unsupervised image classification, including an overview of the ISODATA and k-means algorithms, and to provide students with practical experience of its use by means of an ENVI practical.
An unsupervised classifier does not compare pixels to be classified with any prior information. Rather, it examines a large number of unknown data points and divides them into classes based on properties inherent to the data themselves.
Unsupervised image classification is based entirely on the automatic identification and assignment of image pixels to spectral groupings. It considers only spectral distance measures and involves minimum user interaction. This approach requires interpretation after classification. The user often specifies the number of classes to find and these classes are anonymous – i.e. it is up to the user to define their physical meaning.
In general terms, an unsupervised classifier requires the following parameters to be specified by the user:
- Number of classes
- Number of bands
- Spectral distance or radius in spectral distance
- Spectral space distance parameters when merging clusters
Unsupervised classification begins with a spectral plot of the whole image, on which the required number of class centres are initiated.
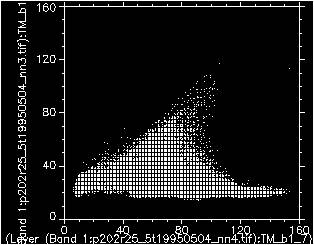
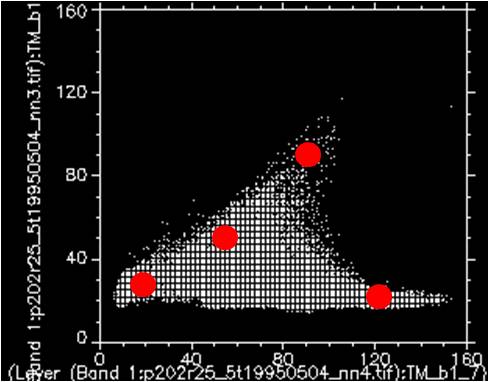
Classification proceeds by an initial separation of the space into regions associated with each class, followed by iterative modification of the class boundaries, with regard to class statistics such as mean, variance, standard deviation, minimum and maximum values.
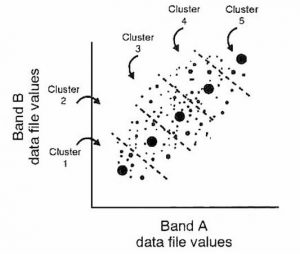
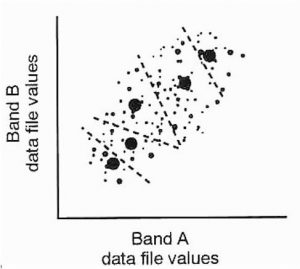
After iteration, the boundaries between the classes must be finalised, in order to produce the classified image:
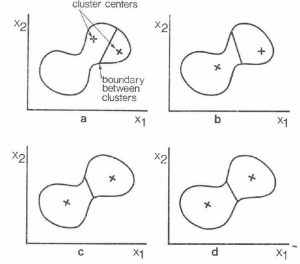

Two common algorithms for creation of the clusters in unsupervised classification are k-means clustering and Iterative Self-Organizing Data Analysis Techinque (Algorithm), or ISODATA.
K-means clustering
N/B: The slides below will not show on the webpage, but you can save/keep them on your computer and view them using the Adobe Flash Player 32 you downloaded earlier
ISODATA
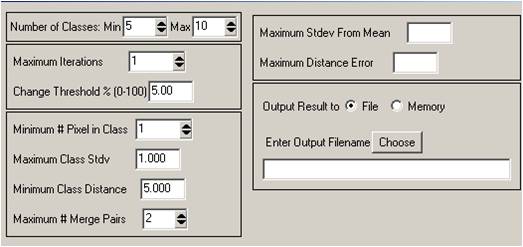
ISODATA is in many respects similar to k-means clustering but we can now vary the number of clusters by splitting or merging. ISODATA requires the user to select the following parameters:
- Minimum number of pixels per cluster
- Desired (approximate) number of clusters
- Maximum spread parameter (standard deviation) for splitting
- Maximum distance separation for merging
- Maximum number of clusters that can be merged
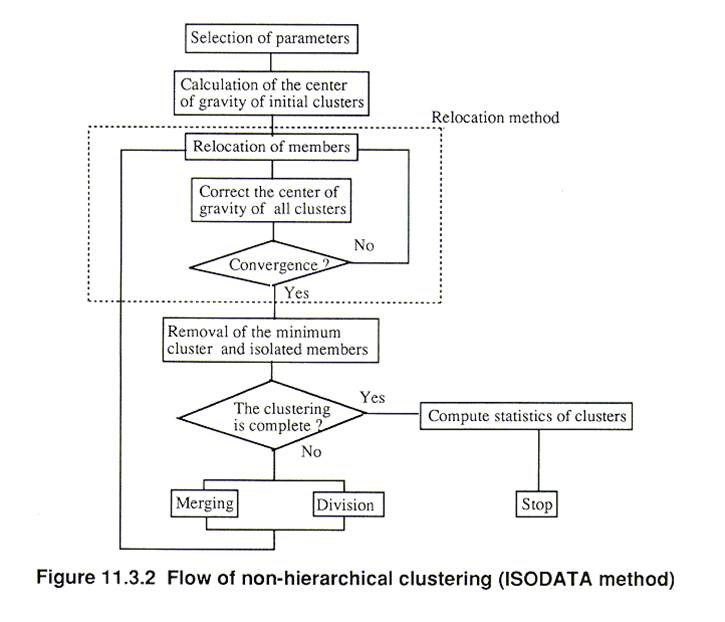
The general operation of the ISODATA algorithm is shown below. The stages represented at the top of the figure are the same as in k-means classification. The differences appear at the stage where removal of the minimum cluster and isolated members are considered. At the end of the process, merging occurs if the distance between two clusters falls below the specified threshold distance and splitting if the standard deviation within a cluster is greater than the specified threshold.
The practical operation of ISODATA is illustrated in the following presentation which demonstrates the circumstances which may lead to a cluster split:
N/B: The slides below will not show on the webpage, but you can save/keep them on your computer and view them using the Adobe Flash Player 32 you downloaded earlier
Unsupervised Classification Practical
Link to the practical can be found here.