We have a prototype!
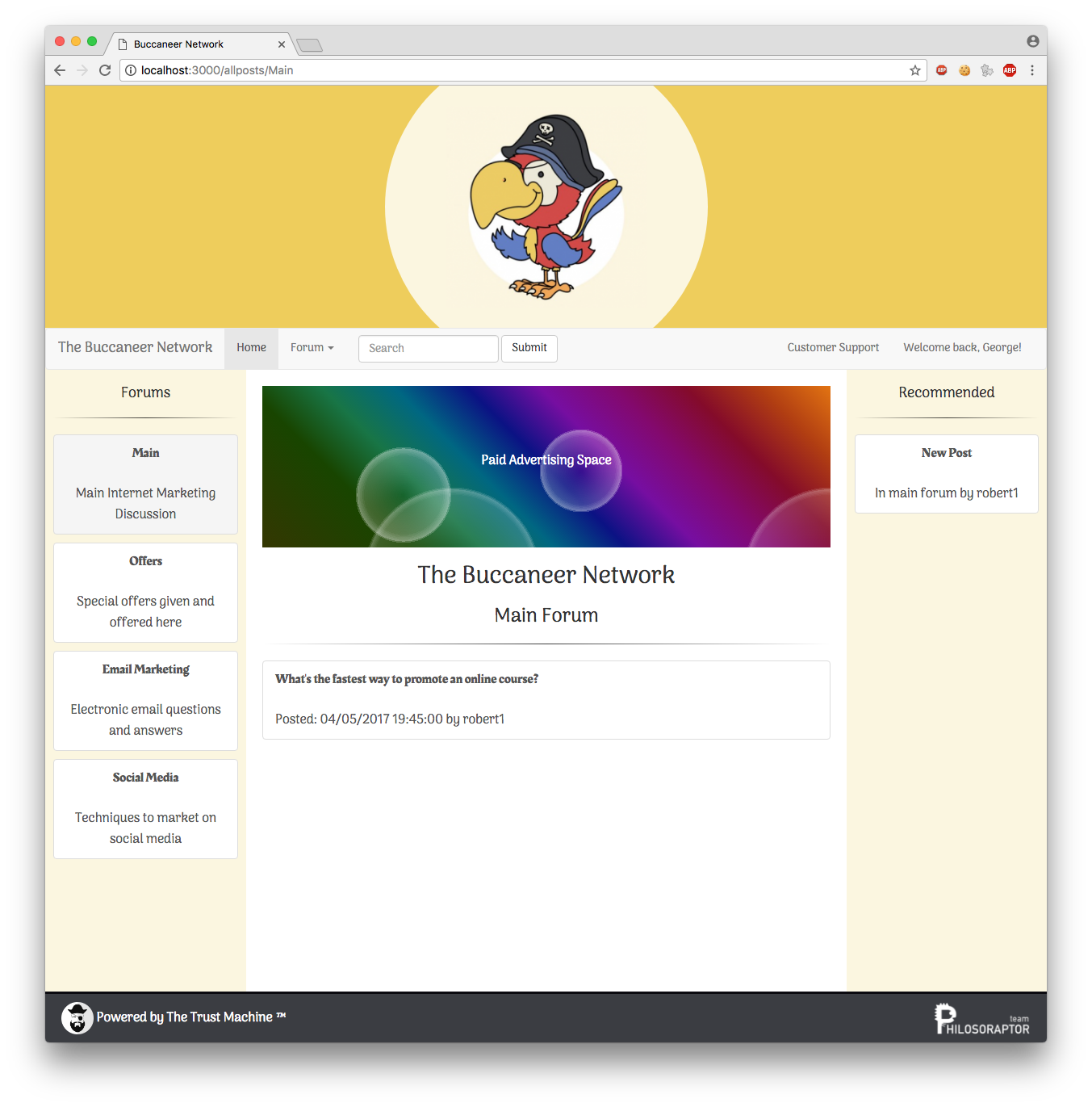
This mock up is a very, very basic mock-up of what could be achieved if this project were to go ahead.
You can visit it here.

We have a prototype!
This mock up is a very, very basic mock-up of what could be achieved if this project were to go ahead.
You can visit it here.
Trust, as we have seen, is a complex thing to model. To quantify it we need to look at a variety of parameters e.g. User behaviours, user provenance and user context. Each of these parameters will modify the trust value. However not all will be used in every setting. We will need different flavours of trust calculation and ways of keeping track of which was used to construct each trust calculation. Designing code to implement a complex model of trustworthiness is going to be a challenge, particularly if we want maintainable code built along proper Object Oriented design principles. Continue reading
The success of any large, and/or challenging software engineering project depends to a great extent on the use of a software development methodology. Using a well thought out methodology allows an ordered systematic development of the product. It creates a working environment in which each team member can communicate using a vocabulary defined by the methodology. It also facilitates the development in an ordered way with clearly defined stages which can be monitored communicated and managed to produce the end product robustly and efficiently. Continue reading
These are an initial set of functional requirements for the Trust Machine. In keeping with Agile software development principles these will be modified and developed on a regular basis throughout all phases of the development as a result of meetings with stakeholders. These meetings should ideally occur on a weekly basis at the very least and will review the requirements as a priority objective at each meeting. Continue reading
In this short video, I discuss some of the main requirements for an implementation technology, and also discuss three potential approaches to building the Buccaneer network.
Below is a UML Use-case diagram for the Trust Machine. It has three actors: Continue reading
In order for us to produce the metrics we require we need to understand the various types and models of trust and algorithms available. Continue reading
One of the methods we propose for building our trustworthiness metric is to establish a single identity for our users by linking their Trust Machine identity to their other online identities on sites such as Ebay, Facebook and Twitter. The aim is to link an account to one on another service and only allow one link per Trust Machine user, so that once a profile has been used to create a Trust Machine account it can never linked to another one. Continue reading
Our project has two inter-dependant components, both of which are vital to each other. The web application is a business case that we have identified as having immense potential but one that fails because for lack of an effective user trust model. The trust application solves this problem but cannot be built without a use case to build it around and demonstrate its viability. This puts us in the enviable position of having two excellent products for the price of one!
However they will only be excellent if we choose the right technology stack… Continue reading
In order to make development of the prototypes easier, we requested a virtual machine from the University which will act as our development web server. The prototypes will appear on the server.
How do I access it, I hear you cry?
You need to be inside the University VPN or actually using a computer inside the University network. Then, simply navigate to:
svm-gc5g13-buccaneer.ecs.soton.ac.uk
And as soon as a web page is available, this is where you will see it. The domain name isn’t pretty, but at the end of the day it’s there so we can easily share our prototypes!